
Compressing Shor's Algorithm
QMill Circuit Compression



I had a chance to play with QMill Circuit Compression and got an unexpected outcome. I was expecting this to be an exercise in which I would compare QMill to other circuit compression techniques, but that’s only a part of the story.
Thank you, Classiq.
I don’t remember how old this code is, but once upon a time I used the Classiq synthesis engine to generate OpenQASM 2.0 for factoring 15 with Shor’s algorithm. It’s been in my library ever since, and what better way to get attention than to reduce the resource requirements for executing Shor’s algorithm? To keep the playing field level, this file was the starting point for all of the circuit compression experiments executed for this article.
Let’s start with QMill.
QMill sits at the algorithms layer of the stack but stretches up into applications and down into middleware, which is where this circuit compression capability awaits you. I leveraged the LUMI supercomputer, which used machine learning to compress my circuit in segments. The software looks locally for compression opportunities, initially transpiling with Qiskit optimization level 3 and then compressing the segment further. Importantly, the unitary is preserved so that nothing important is removed. Impressively, memory limitations haven’t been reached yet, but with sufficient credits I sure would be happy to stress test it.
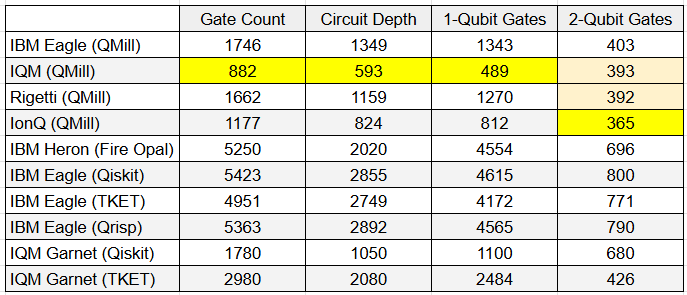
That was unexpected.
Multiple backends are available, so why not use them all? What caught me by surprise is that I have been saying for a while that I prefer IBM Eagles over IBM Herons, and that I prefer IQM and Rigetti over IBM, even though the publicized metrics say that’s backward. Let’s break it down:
IQM and Rigetti offer better qubit connectivity than IBM’s Eagles and Herons, and we can see that both of their circuits get compressed more.
The native gatesets are different, so even with the same topology IQM’s circuit gets compressed considerably more than Rigetti’s.
It’s apples and oranges, because QMill supports Eagles and Q-CTRL’s Fire Opal supports Herons, but even the Dracarys Award-winning Fire Opal generates transpiled circuits that are significantly larger than QMill’s.
Even without QMill, we can see that IQM has lightweight circuits compared to IBM, again, thanks to better qubit connectivity and a different gateset.
I haven’t compared all of their transpiled circuits before, so I’ve always justified my preferences anecdotally: the outputs are better. Now I know, and knowing is half the battle.
Anyway, let the record show that even though IonQ wins on 2-qubit gate counts, presumably due to all-to-all connectivity, it would execute far more slowly than its superconducting competitors. Furthermore, and I can’t stress this enough, it is the only circuit that did not simulate accurately. All of the other circuits ran on an ideal simulator and correctly found that the period of 15 is 4. IonQ found a period of 2. I don’t know if that’s a gateset issue, a QMill issue, or a me issue, but it’s an issue.
Let the record further show that I tried to add a few more rows to the table, but I ultimately tapped out. Good grief. The other approaches are highly unlikely to beat QMill at this rate anyway, so they’re just not worth the extensive troubleshooting.
Conclusion
Why “QMill,” I asked. QMill grinds ideas (like wheat) into algorithms you can feed people. I love that, but they may want to start referencing low-calorie foods since the circuits come out so small.
Anyway, the next time someone mentions Google and Oratomic moving Q-Day closer, keep in mind that QMill and IQM put Shor’s algorithm into a corset, squeezing it down quite a bit while still simulating correctly.
Image generated by Google’s language model AI.